Excel转Word
Excel到Word之间的转换
引言
以下是两份Excel,但是内容的呈现不是特别高效,所以打算转到Word报告方便传上企业微信,飞书等
需求:日常工作中,需要对Excel表格的数据进行筛选计算整理,然后将数据做成Word报告。Word报告的格式已经标准化,数据填入Word过程机械化、耗费时间。
本节通过使用Python进行自动化生成Word极大提高效率。
准备工作
使用到Python.docx库
在官方的样例代码可以找到如下
我们将的Excel表格中的有效信息手动输入到Word中为:
结构为:
品牌名称
视频标题
视频脚本
安装python-docx库
打开jupyter
在终端输入pip install -i https://pypi.tuna.tsinghua.edu.cn/simple python-docx
再打开jupyter
新建py note
1 | from docx import Document |
就可以在对应文件夹上找到生成的demo1文档,并且内容如下

对比上面的代码可以知道结构对应的函数
结构为:
品牌名称 标题一 add_heading
视频标题 标题二 add_heading
视频脚本 正文 add_paragraph
输入以下代码:1
2
3
4
5
6
7from docx import Document
document = Document() #就是添加一个新的文档的意思
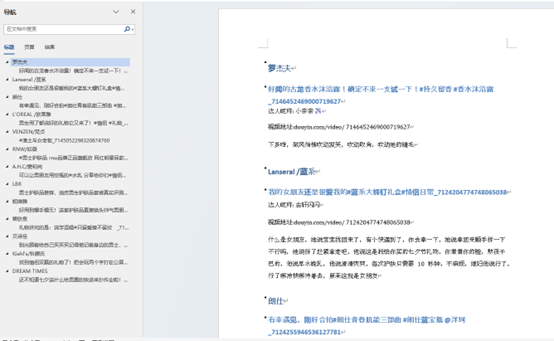
document.add_heading('罗杰夫', level=1)
document.add_heading('答应我,不做臭男人#糟糕是心动的感觉 #恋爱的感觉 @小奈奈✈️ #男神必备 #颜值爆表 ', level=2)
document.add_paragraph('好香的所有风云一次大步往前走')
document.save('demo1.docx')
打开文档可以发现按照想要的格式变成Word了

Excel到Word的基本转换
接下来就是换成所有内容,不断循环上面的代码
使用pandas和for循环进行
使用pandas读取Excel文件
加载数据:
路径:/ video_list.xlsx
/ speech_text.xlsx,都在同一路径下
pandas.read_excel()的作用:将Excel文件读取到pandas DataFrame中。1
2
3import pandas as pd
video_list = pd.read_excel('video_list.xlsx') #读取Excel并传给新建的video_list
speech_text = pd.read_excel ('speech_text.xlsx')
数据合并与处理
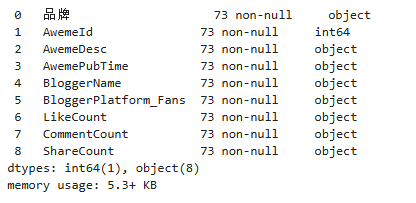
使用info查看参数的类型
video_list.info()
发现id是int类型的,我们转换成字符串
使用 Pandas 的 astype 方法将数据帧(DataFrame)或序列(Series)中的数据类型转换为字符串类型1
video_list['AwemeId'] = video_list['AwemeId'].astype(str)
同理speech_text也是一样1
speech_text['VideoId'] = speech_text['VideoId'].astype(str)
将两表连起来,使用内连接,可以保留两个数据集中同时存在的样本,这些样本的其他特征都会保留,这里键不一样要说出左表和右表的列名
内连接的使用方法
left: 拼接的左侧DataFrame对象
right: 拼接的右侧DataFrame对象
on: 要加入的列或索引级别名称。 必须在左侧和右侧DataFrame对象中找到。 如果未传递且left_index和right_index为False,则DataFrame中的列的交集将被推断为连接键。
left_on:左侧DataFrame中的列或索引级别用作键。 可以是列名,索引级名称,也可以是长度等于DataFrame长度的数组。
right_on: 左侧DataFrame中的列或索引级别用作键。 可以是列名,索引级名称,也可以是长度等于DataFrame长度的数组。
合并两个DataFrame1
merge =pd.merge(video_list, speech_text, how='inner',left_on='AwemeId',right_on='VideoId')
自动化生成Word报告
使用for循环写入代码,实现转换1
2
3
4
5
6
7document = Document()
for i in range(len(merge)):
print(merge.iloc[i]['品牌'])
document.add_heading(merge.iloc[i]['品牌'], level=1)
document.add_heading(merge.iloc[i]['视频标题'], level=2)
document.add_paragraph(merge.iloc[i]['视频文案'])
document.save('demo.docx')
优化报告生成过程
把相同品牌的合并掉,每个品牌只出现一次
思路就判断当前数据的品牌是否与上一条相同,不同就正常打印,相同就不打印名称,当然当索引为0时也正常打印。1
2
3
4
5
6
7
8document = Document()
for i in range(len(merge)):
if merge.iloc[i]['品牌'] != merge.iloc[i-1]['品牌'] or i == 0:
print(merge.iloc[i]['品牌'])
document.add_heading(merge.iloc[i]['品牌'], level=1)
document.add_heading(merge.iloc[i]['视频标题'], level=2)
document.add_paragraph(merge.iloc[i]['视频文案'])
document.save('demo.docx')
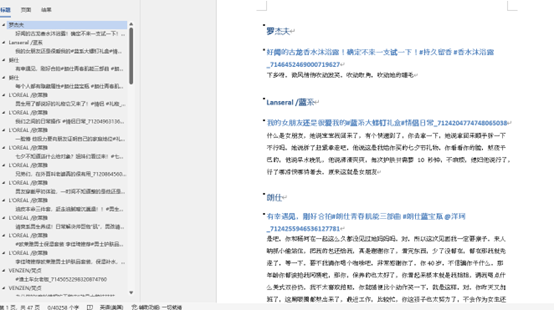
结果如下:

接着优化,将不同列名输入进来,比如昵称,视频地址等1
2
3
4
5
6
7
8
9
10document = Document()
for i in range(len(merge)):
if merge.iloc[i]['品牌'] != merge.iloc[i-1]['品牌'] or i == 0:
print(merge.iloc[i]['品牌'])
document.add_heading(merge.iloc[i]['品牌'], level=1)
document.add_heading(merge.iloc[i]['视频标题'], level=2)
document.add_paragraph(f'达人昵称: {merge.iloc[i]["BloggerName"]}')
document.add_paragraph(f'视频地址:douyin.com/video/ {merge.iloc[i]["AwemeId"]}') #这里字段名要用双引号括起来,不然py会误判结束位置
document.add_paragraph(merge.iloc[i]['视频文案'])
document.save('demo.docx')
结果: